|
|
Главная |
|
|
Пишите |
|

|
Разделы описания (карточки) моей инициативы по развитию России для Росконгресса (РК) в соответствии с их структурой:
Смотрите также страницы:
Размещение в Интернете мирового словарного фонда (МСФ) для поиска слов с похожими звучанием и смыслом для переводчиков, дешифровщиков, компаративистов.
Решения, способствующие развитию цифровой продвинутой аналитики (BigData, ИИ, прогнозные модели и пр.).
Проработанная инициатива.
Предлагаю разместить лексику всех языков мира (живых, вымерших, модельных, реконструированных, древних с ограниченным употреблением) в общей базе данных с доступом через веб-сервис. Поставить каждому слову семантический индекс для их поиска по смыслу. Для этого также надо разработать всеобъемлющее семантическое дерево с вертикальной иерархией и горизонтальными связями между узлами-смыслами. Затем разработать функционал с поиском слов по указанному звучанию или смыслу, а также по похожим фонетическим и семантическим значениям.
Это нужно:
Нужно скопировать тексты копипастных файлов (TXT, DOC, Excel, копипастные PDF) со словарями, найденных в сети (если на них не распространяется авторское право), в текстовые файлы. С некопипастных файлов (DJV, некопипастные PDF) занести тексты с помощью распознования изображений. При отсутствии словарей в сети нужно их отсканировать или занести вручную. Затем структурировать информацию в файлы приемлемых форматов (например, CSV) для последующего экспорта в БД.
Оплата труда
Также будут транспортные расходы для поездок в города с нужными библиотеками.
На главные работы - создание сервиса, поиск и загрузку словарей самых распространённых языков мира - понадобится не меньше 2 лет, а расходов - не меньше 4 млн. руб.
Наши поисковые системы превзойдут зарубежные в точности поиска. Также максимально повысится аналитика любой размещённой и индексируемой информации в Интернете. В свое время наша страна отстала по информационным технологиям. Описываемая цифровая технология позволит взять господство в этой сфере.
Смотрите отдельную страничку.
Компаративисты, этимологи, дешифровщики, компьютерные лингвисты, переводчики, составители словарей, филологи...
Да.
Нет.
Прототип смогу написать сам - а там и опыт появится. Эффект - завоевание лидерской позиции в этой новой технологии - ядре Семантического веба, о котором давно говорят. Но сейчас мода на нейросети, семантический тренд ушел временно в тень. Кстати, к сравнению лексик разных языков (с целью установления уровня их родства) можно подключить и искусственный интеллект.
Ссылка на выступление от первого лица: https://www.lexicons.ru .
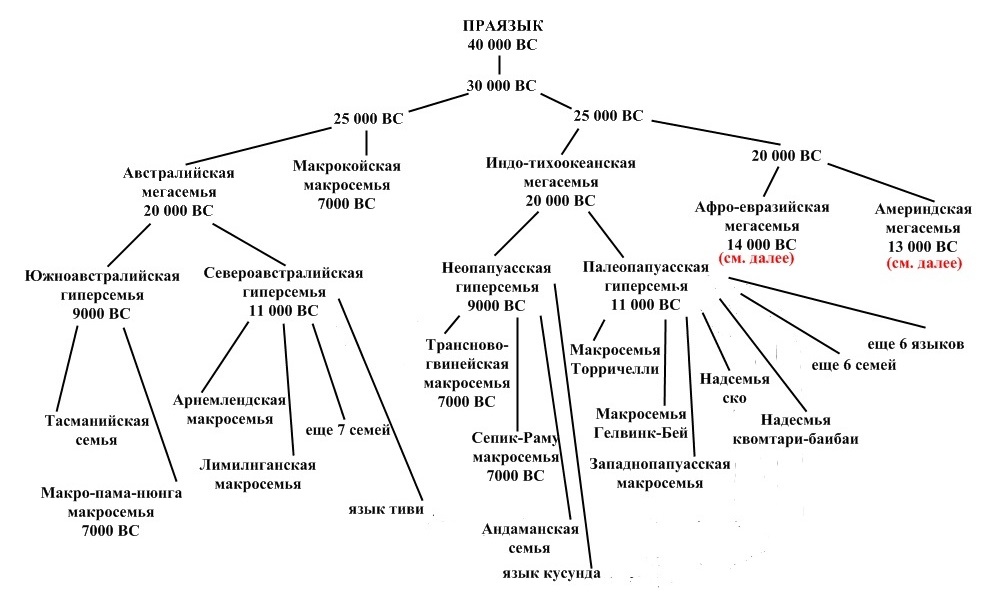
Основные скрин-шоты: lang-monogenetic-scheme.jpg rus-nem-rus.jpg, eng-lexic-levels.jpg, old-writtings-secrets.jpg, old-chinese-palindrom-q.gif, chin-keys1.jpg, chin-keys2.jpg, arabic-consonant-phonems.jpg, arabic-phonetics.jpg,
|

|
Вы можете загрузить 1 изображение в формате png, jpg, jpeg: world-lexic-fund.png [представлена в начале страницы].
Оцифрованные копипастные словари - сетевые и из библиотечных фондов. Разработка поискового механизма в соответствии с ТЗ.
Соавторов нет.
Основные: #предпринимательство, #образовательный, #кадры, #технологический, #социальный, #платформа.
Да.
Идея готова к экспертизе и комментариям.
Ключевые слова для поиска сведений о глобальном фонде слов с нечётким поиском:
На русском языке: всеобщий цифровой словарный фонд, мировой словофонд, глобальный лексический сервис, единая словарная база,
нечеткий фоно-семантический поисковик, приблизительный звуко-смысловой поиск, веб-сервис выборки лексем любых языков;
На английском языке: World Word Fund Service.
|
|
|
|
|
|